Innledning
Gartners Hype Cycle sier at Data Science (datavitenskap) vil være på den såkalte "Plateu of productivity" ... NÅ. Selskaper som har ambisjon om å forme den datadrevne framtiden er godt i gang.
I denne bloggserien "Datavitenskap (DataScience/Bigdata) - hvordan gjør de det?" gjennomgår jeg et utvalg av teknikker vi kan bruke for å skape kunnskap av data*.
I innlegg #2 tar jeg for meg tre nye familier av teknikker:
- klassifisering,
- anbefalingsmotorer (samhandlingsfiltrering - Amazon, Spotify etc.) og
- klyngeteknikker (clustering)
Klassifisering
I klassifiseringgruppen av algoritmer prøver vi å plassere nye objekter (f. eks. en kunde) i forhåndsdefinerte klasser. Det finnes en rekke klassifiseringsteknikker (informatikere kaller det "algoritmer"). Én mye brukt klassifiseringalgoritme plasserer objektet vi skal klassifisere i et en-, to-, tre- eller flerdimensjonalt koordinatsystem(#).
Algoritmen leter etter de objektene som er nærmest objektet vi skal klassifisere. De nærmeste objektene kaller vi naboer.
Tenk deg at naboene allerede er klassifisert og plassert ut i koordinatsystemet. Hver av aksene i det flerdimensjonale koordinatsystemet (eller "rommet") representerer en bestemt egenskap. Vi plasserer det nye objekt i dette koordinatsystemet basert på verdiene for de respektive egenskapene og beregner avstanden til naboene, på samme måte som vi beregner avstanden i vår virkelige tre-dimensjonale tilværelse.
Tenk deg at naboene allerede er klassifisert og plassert ut i koordinatsystemet. Hver av aksene i det flerdimensjonale koordinatsystemet (eller "rommet") representerer en bestemt egenskap. Vi plasserer det nye objekt i dette koordinatsystemet basert på verdiene for de respektive egenskapene og beregner avstanden til naboene, på samme måte som vi beregner avstanden i vår virkelige tre-dimensjonale tilværelse.
Vi bestemmer selv hvor mange naboer vi skal ta med i beregningen. Algoritmen kalles k-nærmeste naboer. K'en indikerer at vi har friheten til å definere hvor mange naboer vi skal vurdere i klassifiseringen.
Eksempel
La oss si vi har en kundedatabase med informasjon om hvem som kjøper et produkt (kjøpere) og hvem som ikke kjøper et produkt (ikke-kjøpere). For alle disse har vi informasjon om alder, kjønn og inntekt, altså 3 egenskaper. Hver av disse 3 egenskapene er representert ved hver sin akse i et koordinat-system.Tenk deg et x, y, og z koordinatsystem med alder langs x-aksen, kjønn langs y-aksen og inntekt langs z-aksen. I tillegg har vi en liste av potensielle nye kjøpere med den samme informasjonen (alder, kjønn og inntekt), men ikke om de er kjøpere eller ikke-kjøpere. Det siste er det vi skal finne ut. Algoritmen finner fram til hvilke av de potensielle kjøperne som har størst sjanse for å kjøpe. Vi klassifiserer de potensielle kjøperne i den nye listen basert på naboenes allerede historisk bestemte klassifisering i kunderegisteret vårt.
I diagrammet under har vi merket kjøpere med blå kvadrater og ikke-kjøpere med røde triangler. En potensiell kjøper er representert ved en grønn sirkel. Vil dette prospektet bli en kjøper? Hva vil algoritmen svare? Vel, det kommer an på...
 |
| Klassifisering Vi bestemmer selv hvor mange naboer vi vil ta med i beregningen. La oss bruke 3 naboer. Vi ser på punktene på innsiden av den hele sirkelen. Der er det to røde ikke-kjøpere og én blå kjøper. Vi spår derfor at den potensielle kjøperen ikke er en kjøper. |
Hvis vi ser på de fem nærmeste naboene, innenfor den prikkete sirkelen, finner vi tre blå kunder og to
røde ikke-kjøpere. Her spår vi at vedkommende er en sannsynlig kjøper. Resultatet blir forskjellig.
Hva kan vi gjøre her? Vi kan for eksempel vekte med hensyn på distansen. Punktene nærmest kan telle mer en punktene lenger unna. Med det som utgangspunkt blir det enda vanskeligere i dette eksemplet å lande på om det er en sannsynlig kjøper eller ikke. Husk da at dét i seg selv også er viktig informasjon.
Algoritmen gir en sannsynlighet for om et prospekt kan komme til å kjøpe eller ikke. I dette tilfellet er det vanskelig å spå.
I eksemplet ovenfor er det veldig lite data. Normalt vil det være store mengder data. Presisjonen vil derfor i praksis være mye bedre.
Begrensinger
Begrensinger
En av utfordringene med k-nærmeste nabo-algoritmen er at den er ressurskrevende. Algoritmen beregner avstanden mellom hvert eneste prospekt og mot alle historiske kjøpere og ikke-kjøpere. I et stort datagrunnlag blir det mange beregninger.
Anbefalingsmotorer (Samhandlingsfiltrering)
Anbefalingsmotorer kan blant annet brukes til å promotere nye tilbud av produkter til deg som det er stor sannsynlighet for at du finner interessante.
Analyser av preferanser til mange individer finner sammenfallende mønstre i smak og behag.
Liker jeg filmen Matrix er det større sjanse for at jeg også liker Minority report. Liker jeg Carpe Diem så er sjansen større for at jeg liker Madcon. Liker jeg ballett så liker jeg kanskje opera.
Vi liker like ting og vi liker også det individer som likner oss liker.
Anbefalingsmotorer beregner hva du sannsynligvis også liker og misliker basert på din og andres historiske adferd.
Liker jeg filmen Matrix er det større sjanse for at jeg også liker Minority report. Liker jeg Carpe Diem så er sjansen større for at jeg liker Madcon. Liker jeg ballett så liker jeg kanskje opera.
Vi liker like ting og vi liker også det individer som likner oss liker.
Anbefalingsmotorer beregner hva du sannsynligvis også liker og misliker basert på din og andres historiske adferd.
Anbefalingsmotorer lager en liste av anbefalinger på to måter:
Motoren finner sammenliknbare kunder og foreslår produkter andre sammenliknbare kunder har kjøpt.
I tabellen under ser vi at kundene har en rating per produkt. Rød er topp rating og blå er laveste rating. Vi finner de kundene som har likest rating over produktene og vi foreslår nye produkter som andre liknende kunder har gitt en høy rating.
Innholdsbasert filtrering ser på egenskapene på produktene. Poenget er å tilby produkter med liknende egenskaper som du tidligere har kjøpt eller gitt høy rating.
- samhandlingsfilter og
- innholdsbasert filter.
Motoren finner sammenliknbare kunder og foreslår produkter andre sammenliknbare kunder har kjøpt.
I tabellen under ser vi at kundene har en rating per produkt. Rød er topp rating og blå er laveste rating. Vi finner de kundene som har likest rating over produktene og vi foreslår nye produkter som andre liknende kunder har gitt en høy rating.
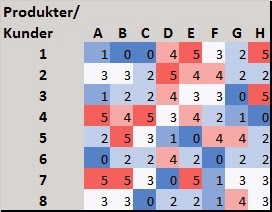 |
| Samhandlingsfiltrering - ratingtabell |
Musikkanalene, Last.fm og Pandora Radio benytter hver sin teknikk.
Pandora bruker egenskapene til sangen eller artisten hentet ut fra musikkens "dna" (400 forskjellige egenskaper ved musikken). Musikkstasjonen finner liknende musikk. Brukerens tilbakemelding raffinerer resultatet og nedtoner eller uthever egenskaper blant de 400 egenskapene. Dette er innholds-basert filtrering.
Last.fm setter opp en musikkstasjon med anbefalte sanger basert på observasjoner av band, artister og individuelle sanger brukeren har lyttet til. Denne adferden sammenliknes med andre brukeres adferd. Last.fm spiller spor som ikke opptrer i brukerens bibliotek, men som ofte er spilt av andre brukere med liknende interesse. Her utnyttes andres adferd. Teknikken kalles derfor samhandlingsfiltrering.
Begrensinger
En ulempe med samhandlingsfiltrering er at algoritmen krever mye innsamlet data. Den gir liten verdi i starten. Innholdsfiltrering virker med en gang, men er mer begrenset. Algoritmen finner kun liknende musikk, og det er jo litt kjedelig i lengden. Samhandlingsfiltrering utvider horisonten basert på andres adferd.
Klyngeteknikker (Clustering)
Klyngealgoritmene likner på k-nærmeste nabo-algoritmen, med den fundamentale forskjellen at vi ikke har forhåndsdefinerte klasser å plassere objektene i. Vi kan derfor bare se på hvordan objekter grupperer seg og ikke hvilken klasse objekter tilhører. Algoritmene brukes blant annet ofte til å plassere kunder i kundesegmenter. Nå vi har segmentert kundene kan vi finne ut av hva som kjennetegner disse segmentene for deretter å iverksette tiltak skreddersydd for den enkelte gruppering.
Under ser vi et diagram som visualiserer en håndfull av de mest brukte klyngealgoritmene. Diagrammet viser forskjellige måter å klynge forskjellige datasett. Eksemplene viser hvordan forskjellige teknikker egner seg for forskjellige type datasett. En viktig analyseøvelse er å forstå dataene. Forståelse av disse er avgjørende for velge riktig algoritme.
 |
| Klyngeteknikker |
Avhengig av hvilken algoritme som brukes kan det være utfordrende å tolke resultatene.
Videre analyser som bidrar til å forstå segmentene er viktig. En oppgave er ofte å prøve å forenkle. Hvilke egenskaper er de som virkelig utgjør en forskjell for å besvare våre spørsmål? Det er et eget tema for en senere blogg.
Hva kjennetegner egentlig de forskjellige segmentene?
Hvordan kan jeg best yte service til de forskjellige kundesegmentene?
Hvilke produkter er mest interessante?
Hva slags type klær bruker dette segmentet?
Hvor bor kundene?
Er kundesegmenter lojale eller ikke?
Tjener vi penger på dem?
|
I det tredje innlegget tar jeg for meg to nye familier av algoritmer:
- Support Vector Machines og
- Nevrale nettverk.
Grensene mellom klassene trekkes slik at den totale avstanden mellom klassene blir størst mulig.
Nevrale nettverk er et vanskelig, men veldig spennende(!) tema. Nevrale nettverk har revolusjonert datavitenskapen de siste årene.
Resultatene som kommer ut av nevrale nettverk kan oppleves som magi, riktignok med den store forskjellen at algoritmen gir ekte anvendbare resultater.
Mer om dette i neste innlegg.
Mer om dette i neste innlegg.
# Faktisk bruker veldig mange av datavitenskaps-teknikkene et slikt koordinatsystem.
*Innlegget er en mix av egne erfaringer, fritt omarbeidet del av Alex Jones artikkel om Bigdatateknikker og fra boken som Data Science for Business av Provost og Fawcett.

Espen Remman
Rådgiver/Partner
Chronos AS
tlf. +47 97 55 70 21

Ingen kommentarer:
Legg inn en kommentar